Superstore Global: Otimização Logística e Rentabilidade
Power BI
Python
DB Cloud
DAX
ETL
API
Objetivo do Projeto
Desenvolver uma solução de Business Intelligence de ponta a ponta, utilizando Python para ETL e SQL em Nuvem (Aiven) para integrar métricas de vendas e logística em um ambiente escalável. O foco foi estruturar um ecossistema de dados que forneça suporte à tomada de decisão estratégica através de uma visão clara da performance global.
Problema de Negócio
A organização apresentava inconsistência na lucratividade entre diferentes territórios, apesar do alto volume de vendas. O projeto visou mapear "pontos cegos" operacionais, fornecendo uma visão diagnóstica sobre como o Ticket Médio e os custos de frete impactavam a margem líquida, permitindo a identificação de mercados deficitários e gargalos logísticos para futuras ações corretivas.

Resultados e Insights
Principais Descobertas
Identificação de 6 países na "Zona Crítica" (ex: Philippines com margem de -8,79%), onde o alto volume de receita é neutralizado por descontos agressivos (média de 34,6%).
"O Custo Médio Global por Frete é de $54,43, mas a análise regional revela disparidades críticas: a região Central concentra o maior custo logístico, com frete médio de $27,69 por envio — valor que, em categorias de baixo ticket médio, supera o lucro unitário gerado e comprime diretamente a margem líquida.
Os EUA consolidam-se como operação modelo, mantendo margem superior a 30%, servindo de parâmetro para a otimização das demais regiões.
Recomendações Acionáveis
Limitar descontos a no máximo 20% em subcategorias com Margem Bruta abaixo de 15% — especialmente Mesas (2,2%) — para recuperar entre 2 e 4 pontos percentuais de margem líquida
Apresentar aos gestores de logística os custos de frete desproporcionais por região, facilitando a renegociação de contratos baseada em dados reais de performance.
Estabelecer o monitoramento contínuo das "bolhas de risco" (Zona Crítica) para priorizar ações de correção imediata na correlação entre custo de envio e lucratividade.
Lógica de Tratamento & ETL
SQL - Modelagem Dimensional e Governança
-- 1. Criação da Dimensão Produto com geração de Surrogate Key (SK) para integridade
CREATE OR REPLACE VIEW dProduto AS SELECT
ROW_NUMBER() OVER (ORDER BY ID_Produto, Nome_Produto) AS ID_Produto_SK,
ID_Produto AS Codigo_Original,
Nome_Produto,
Categoria,
Sub_Categoria
FROM (
SELECT DISTINCT ID_Produto, Nome_Produto, Categoria, Sub_Categoria
FROM fVendas
) AS subquery;
-- 2. Estruturação da Dimensão Localidade com duplicação de registros geográficos
CREATE OR REPLACE VIEW dLocalidade AS SELECT
ROW_NUMBER() OVER (ORDER BY Pais, Estado, Cidade) AS ID_Localidade,
Pais,
Estado,
Regiao,
Cidade
FROM(
SELECT DISTINCT Pais, Estado, Regiao, Cidade
FROM fVendas
) AS subquery;
-- 3. Dimensão Cliente focada na segmentação de base
CREATE OR REPLACE VIEW dCliente AS
SELECT DISTINCT
ID_Cliente,
Nome_Cliente,
Segmento
FROM fVendas;
-- 4. Consolidação da Tabela Fato vinculando dimensões via IDs para otimização de performance
CREATE OR REPLACE VIEW fVendas_Final AS
SELECT
f.*,
l.ID_Localidade,
p.ID_Produto_SK
FROM fVendas f
LEFT JOIN dLocalidade l
ON f.Pais = l.Pais
AND f.Estado = l.Estado
AND f.Cidade = l.Cidade
LEFT JOIN dProduto p
ON f.ID_Produto = p.Codigo_Original
AND f.Nome_Produto = p.Nome_Produto;
Python - Integração e Tratamento
Limpeza e Tratamento de Dados
# Mapeamento e correção de encoding (colunas corrompidas e caracteres chineses)
for col in df.columns:
if "è°°" in col or "记录数" in col:
df = df.rename(columns={col: "N_Registros"})
# Tradução integral dos dados para o mercado brasileiro
for coluna, dicionario in mapeamento_conteudo.items():
if coluna in df.columns:
df[coluna] = df[coluna].astype(str).str.strip().map(dicionario).fillna(df[coluna])
Engenharia de Novas Métricas
# Integração com API externa para conversão monetária dinâmica
taxa_dolar = buscar_cotacao_dolar()
# Criação de indicadores de performance (KPIs) diretamente no pipeline df['Tempo_Envio_Dias'] = (df["Ship Date"] - df["Order Date"]).dt.days
df['Vendas_BRL'] = df['Sales'] * taxa_dolar
df['Margem_Lucro'] = df['Profit'] / df['Sales'].replace(0, np.nan)
Automação da Carga Cloud
# Configuração da carga para banco de dados gerenciado (Aiven MySQL)
# Garantindo a integridade referencial com a definição de Primary Key
sql_create_table = """
CREATE TABLE IF NOT EXISTS fVendas (
ID_Linha BIGINT PRIMARY KEY,
Categoria TEXT, Pais TEXT, Data_Pedido DATETIME,
Lucro_USD DOUBLE, Vendas_BRL DOUBLE, Margem_Lucro DOUBLE
-- [Demais colunas omitidas para brevidade]
);
"""
# Execução da carga via SQLAlchemy
df_final.to_sql(name="fVendas", con=engine, if_exists='append', index=False)
Medidas DAX em Destaque
Métrica Dinâmica do Painel
Métrica Dinâmica do Painel =
VAR selecao = SELECTEDVALUE('Tabela_Selecao'[Parâmetro Pedido])
RETURN
SWITCH(
selecao,
1,[Lucro Bruto],
2,[Lucro Liquido],
3,[Margem Líquida %],
4,[Qtd Vendida],
5,[Receita Líquida (RL)],
6,[Custo Envio],
7,[Impacto Envio %]
-- [Métrica abreviada para exebição]
)
Crescimento Mensal (MoM%)
Crescimento Mensal (MoM%) =
VAR ValorAtual = [Métrica Dinâmica do Painel]
VAR ValorPassado = CALCULATE([Métrica Dinâmica do Painel], DATEADD('dCalendario'[Date], -1, MONTH))
VAR Percentual = DIVIDE(ValorAtual - ValorPassado, ValorPassado)
VAR Icon = SWITCH(
TRUE(),
Percentual > 0 , UNICHAR(11165), -- Seta para cima
Percentual < 0, UNICHAR(11167), -- Seta para baixo
"-"
)
RETURN
Icon & " " & FORMAT(ABS(Percentual), "0.0%")
Cor Dinâmica de Alerta
Cor Dinâmica de Alerta =
VAR selecao = SELECTEDVALUE('Tabela_Selecao'[Parâmetro Pedido])
VAR ValorAtual = [Métrica Dinâmica do Painel]
VAR ValorPassado = CALCULATE([Métrica Dinâmica do Painel], DATEADD('dCalendario'[Date], -1, MONTH))
VAR Percentual = DIVIDE(ValorAtual - ValorPassado, ValorPassado)
VAR EhCusto = (selecao = 6 || selecao = 7)
RETURN
SWITCH(
TRUE(),
ISBLANK(Percentual) || Percentual = 0, "#e8b62f", -- Estável
-- Se for custo e subiu: Ruim (Vermelho). Se caiu: Bom (Verde)
EhCusto && Percentual > 0, "#d24126",
EhCusto && Percentual < 0, "green",
-- Se for faturamento e subiu: Bom (Verde). Se caiu: Ruim (Vermelho)
Percentual > 0, "green",
"#d24126"
)
Performance da Categoria Detratora
Filtro de Ranking Dinâmico =
-- 1. Observa qual métrica o usuário quer analisar no momento
VAR MetricaSelecionada = SELECTEDVALUE('Tabela_Selecao'[Parâmetro Pedido])
-- 2. Calcula o ranking comparando o país atual com os demais visíveis
VAR Ranking =
RANKX(
ALLSELECTED('dLocalidade'[Pais]),
SWITCH(
MetricaSelecionada,
2, [Lucro Liquido],
3, [Margem Líquida %],
7, [Impacto Envio %]
),
,
DESC
)
-- 3. Retorna um sinalizador (1 ou 0) para ser usado no filtro do visual
RETURN
IF(Ranking <= 10, 1, 0)
Performance da Categoria Detratora
Performance da Categoria Detratora =
-- Descobre qual é a subcategoria detratora ignorando o mês do gráfico de linha
VAR CategoriaCritica = CALCULATE([SubCategoria Prejuizo], ALLSELECTED('dCalendario'))
RETURN
-- Isola o cálculo apenas para essa subcategoria específica
CALCULATE(
[Lucro Liquido],
KEEPFILTERS('dProduto'[Sub_Categoria] = CategoriaCritica)
)
Análise Vertical DRE %
Análise Vertical DRE % =
VAR ValorLinha = [Valores DRE]
VAR ReceitaLiquida = CALCULATE([Valores DRE], FILTER(ALL('Mascara DRE'), 'Mascara DRE'[Ordem Descrição] = 3))
RETURN
DIVIDE(ValorLinha, ReceitaLiquida)
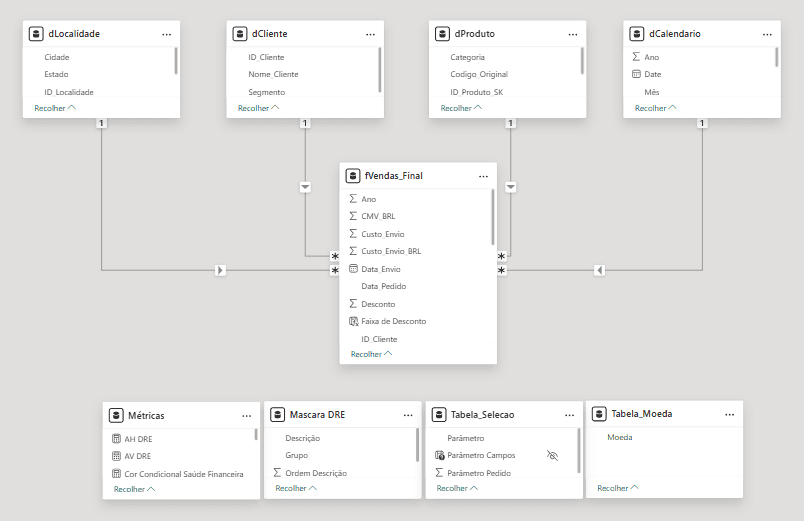
Modelagem de Dados
Arquitetura Star Schema
Implementação de modelagem dimensional para otimização de performance e simplificação das fórmulas DAX. A centralização da tabela fato (fVendas_Final) conectada a dimensões claras (Produtos, Clientes, Localidade e Calendário) garante integridade referencial e filtros bidirecionais eficientes, permitindo análises complexas de Inteligência de Tempo com baixo custo computacional.
Vamos Transformar dados em estratégia? Contate-me!




Disponível para oportunidades presenciais, remotas e híbridas
© 2026 - Portfólio de Beattriz Sant’ana